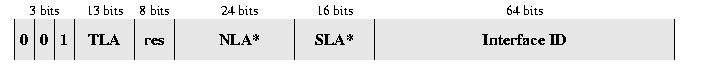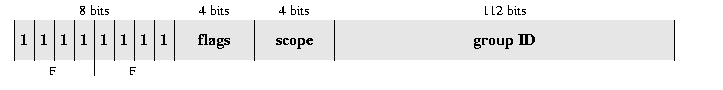 |
IPv4, version actuelle du protocole Internet, commence à atteindre ses limites et laissera sa place à son successeur IPv6. Nous décrirons dans un premier temps le protocole IPv6 ainsi que le plan d'adressage utilisé. Ensuite, nous présenterons ICMPv6 et la découverte des voisins (neighbor discovery), protocoles associés à IPv6. Enfin, nous parlerons d'une grande nouveauté d'IPv6 : la configuration automatique.
L'Internet est né sous le nom d'«ARPANET», réseau conçu en 1969
par l'agence américaine ARPA (Advanced Research Projects
Agency). L'Internet a vu le jour sous sa forme
actuelle en 1983
comme résultat de la mise en oeuvre de la suite
protocolaire TCP/IP (Transmission Control Protocol / Internet
Protocol) dans le système Unix BSD (Berkeley System
Distribution). La pile TCP/IP est devenue par la suite une partie
intégrante, fournie en standard dans tous les systèmes Unix. Dès lors,
le réseau Internet a connu une croissance de plus en plus rapide, jusqu'à
couvrir toute la planète en l'espace d'une dizaine d'années.
L'Internet (Inter-Networking ) est bâti sur le modèle de
catenet qui consiste à interconnecter des réseaux. Les
protocoles TCP/IP qui régissent ce réseau mondial n'émettent aucune
hypothèse sur le
type d'infrastructure ou d'équipement utilisés. Ils considèrent que les
extrémités, ou points terminaux (ordinateurs), sont des objets
«intelligents» et capables de traitements évolués. En d'autres termes,
un choix a été fait pour Internet : celui de mettre l'intelligence
dans les équipements terminaux et non pas dans le réseau.
L'Internet (et plus particulièrement le protocole IP) est victime de son succès, à tel point qu'il est devenu urgent de passer de sa version actuelle (IPv4) à la version IPv6, ou Protocole Internet nouvelle génération. La transition d'IPv4 à IPv6 ne remet pas en question le modèle TCP/IP. Bien au contraire, les travaux de l'IETF (Internet Engineering Task Force, organisme de standardisation des protocoles de l'Internet) ont été menés dans le sens du renforcement de ce modèle. Ainsi, le protocole IPv4 a subi un toilettage complet et de nouveaux protocoles sont venus apporter leur soutien à IPv6 afin de mieux s'adapter aux besoins dans l'Internet (mobilité, sécurité, classes de service, ...). Soulignons que le terme IP que nous utilisons désigne le protocole Internet et couvre donc IPv4 et IPv6. Les termes IPv4 et IPv6 seront employés s'il y a un risque d'ambiguïté.
Cette section est consacrée à la version actuelle du protocole IP (IPv4). Dans un premier temps, nous rappèlerons brièvement ce qu'est le modèle TCP/IP . Ensuite, nous présenterons de manière synthétique les fonctions remplies par le protocole IPv4 ainsi que ses principes fondamentaux. Il est essentiel de bien les comprendre car ils ont été conservés pour IPv6.
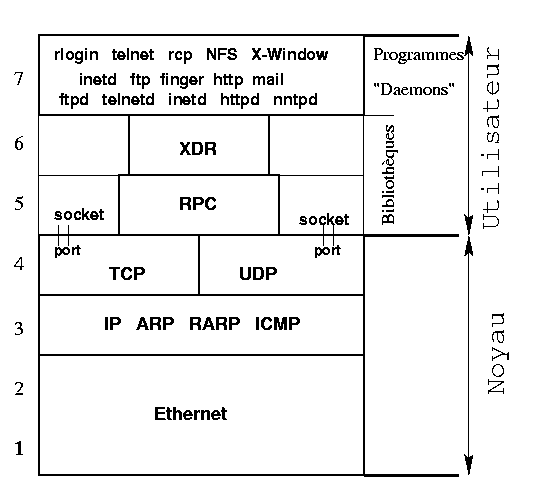
Il est souvent utile, ne serait-ce que pour des raisons pédagogiques, de décrire la pile protocolaire TCP/IP par comparaison avec le modèle de référence OSI (Open Systems Interconnection) à sept couches.
Si tout le monde s'accorde à présenter la suite TCP/IP
comme un modèle à plusieurs couches, le nombre de ces couches ne fait
pas l'unanimité. En effet, ce modèle est généralement vu (selon
l'école) comme une pile à quatre ou à cinq niveaux fonctionnels. La
figure 1 rappelle la
superposition de la pile protocolaire
TCP/IP dans un système Unix avec les sept couches du modèle OSI.
Notons qu'Ehternet est la technologie d'infrastructure réseau la plus
fréquemment utilisée et qu'à sa place peuvent exister d'autres
infrastructures telles Token Ring, FDDI, PPP, ATM, ....
Dans la suite de cet article, nous nous intéressons uniquement à la couche Internet (niveau 3 du modèle OSI) dans laquelle on trouve le protocole IP et ses protocoles associés. Pour IPv4, il s'agit essentiellement des protocoles ARP, RARP, ICMP et IGMP et des différents protocoles de routage (RIP, OSPF, ...). Nous verrons plus loin les protocoles associés à IPv6 comme la découverte des voisins et ICMPv6.
Le protocole IP assure essentiellement l'adressage et l'acheminement des données. D'autres protocoles de la couche réseau garantissent le fonctionnement d'IP, comme la résolution d'adresse IP en adresse physique (adresse MAC), le contrôle d'IP (ICMP) ou le calcul des tables de routage.
Une adresse IPv4 est un mot de quatre octets. On le représente
généralement
en notation décimale comme une suite de quatre nombres
séparés par des «.» (par exemple 128.93.3.25). Selon la valeur des
premiers bits de poids fort, une adresse IPv4 est dite de classe A, B,
C ou D. Pour une adresse de classe A, B ou C, et au delà des bits qui
déterminent la classe, une première partie de l'adresse sert à coder
l'identificateur du réseau («net_id», il contient tous les bits qu'on
en commun toutes les adresses des machines d'un réseau) et le reste
sert à coder
l'identificateur de la machine hôte dans ce réseau
(«host_id»). La figure 2 illustre la
classification des adresses IPv4.
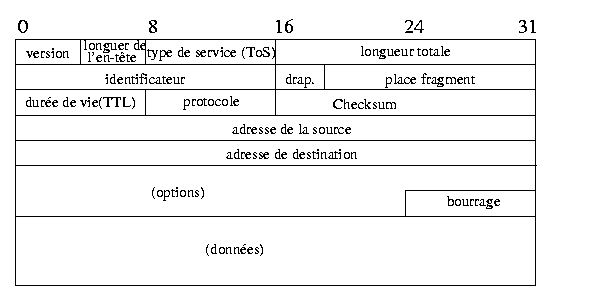
Les données sont véhiculées à travers l'Internet dans des datagrammes
que l'on appelle communément paquets1. La figure 3 rappelle le format d'un datagramme
IPv4.
Les architectes de l'Internet ont retenu deux principes fondamentaux :
L'Internet des années 1970 (l'ARPANET en fait), pour lequel IPv4 était
parfaitement adapté, n'a plus grand chose à voir avec celui
d'aujourd'hui. En effet personne à l'époque n'avait prévu la
croissance exponentielle et démesurée de la taille que
pourrait atteindre l'Internet.
Au début des années 1990, plusieurs problèmes se posent. D'abord, les adresses de classe B allaient bientôt être épuisées. Ce manque d'adresses n'a pas été prévu dans l'Internet originel. D'autre part, le nombre de réseaux dans l'Internet ayant crû de manière vertigineuse, les tables de routage sont devenues de plus en plus volumineuses, entraînant ainsi un grand risque de saturation de mémoire dans les routeurs. Pour pallier ce problème, une méthode d'agrégation de réseaux contigus en un seul préfixe est conçue : Classeless Inter-Domain Routing [RFC1519]. CIDR, qui propose une agrégation de l'adressage, est exploitée dans les protocoles de routage et permet de gérer simplement des ensembles de réseaux. Plus précisément, depuis quelques années, des blocs contigus d'adresses réseau de classe C sont alloués aux fournisseurs d'accès Internet. Cette méthode a pour avantage d'agréger au mieux les préfixes de routage des clients et de satisfaire leurs demandes en adresses IPv4 tout en limitant au maximum les gaspillages.
Prenons l'exemple d'un réseau de classe C dont l'adresse est 192.168.2.0/24 (cette notation signifie que les 24 premiers bits de l'adresse codent l'adresse du réseau). Un découpage en plusieurs sous-réseau, par exemple pour distinguer les réseaux Ethernet des réseaux ATM ou autres, est possible en fixant les premiers bits du dernier octet en fonction du nombre de sous-réseaux désirés. Ainsi, un administrateur souhaitant avoir 4 sous-réseaux de 64 adresses utilisera comme masque de sous-réseau 255.255.255.240 pour chacun d'eux. Leurs adresses seront donc 192.168.2.0/28, 192.168.2.64/28, 192.168.2.128/28 et 192.168.2.192/28. Nous verrons que ceci est fait de manière totalement naturelle en IPv6.
Un autre palliatif est le recours à la traduction d'adresses «NAT»
(Network Address Translator) [RFC1631] qui utilisent un plan
d'adressage «privé» à l'intérieur d'un site (au sens d'un ensemble de
réseaux logés sur un même site géographique).
Ces adresses ne
permettent pas de communiquer directement avec une machine située à
l'extérieur du site. Les communications avec l'extérieur étant quand
même nécessaires, on a recours à un artifice pour les réaliser : le
routeur de sortie de site «converti» toutes les adresses privées
en une ou plusieurs adresses officielles. Ce routeur établit donc les
communications en lieu et place des machines internes au site. Un tel
mécanisme ne nécessite que quelques adresses IP officielles pour
l'ensemble d'un site pouvant contenir plusieurs milliers de
machines, ce qui constitue manifestement une violation du principe de
«bout en bout». Cette
approche est suffisante pour utiliser des applications simples comme
le Web mais pénalise lourdement la mise en place de nombreuses autres
applications. De plus, elle ne permet pas la mise en oeuvre de
solutions à sécurité forte basées sur la cryptographie. Dans IPv6, la
sécurité est partie intégrante, alors qu'elle est "ajouté" dans
IPv4. En effet, IPSec stipule que toute procédure
d'authentification ou communication chiffrée doit être précédée par la
négociation d'une « association de sécurité » (AS) au niveau de
chacune des deux extrémités de la connexion. Chaque AS spécifie les
différents algorithmes cryptographiques utilisés.
Prenons par exemple, dans IPv6, le cas d'un protocole
d'authentification à clés publiques.
L'échange de clés se fait de "la main à la
la main", sans aucun intermédiaire. En IPv4, avec NAT, comme la
connexion passe par le serveur qui effectue le
masquarading, celui-ci doit échanger des clé avec chacun des
intervenants, ce qui accroît le nombre de clés (on passe de 2 à 4) et
donc les risques et le coût de la transaction.
Les problèmes posés par l'épuisement des adresses disponibles et l'explosion des tables de routage, repoussés quelques temps grâce à ces «rustines», restent entiers. Il est donc devenu impératif de s'y attaquer en s'appuyant sur les principes fondamentaux qui ont fait la réussite de l'Internet. C'est à cette tâche que s'attèle depuis 1992 l'IETF, l'organisme de standardisation de l'Internet, pour spécifier la nouvelle génération du protocole IP, appelée IPv6.
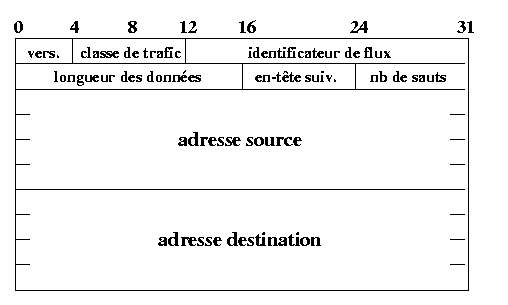
En plus de la modification de la taille des adresses, ce qui conduit à une taille d'en-tête de 40 octets, le protocole IP a subi un toilettage reprenant l'expérience acquise au fil des ans avec IPv4. Le format des en-têtes IPv6 est simplifié et permet aux routeurs de meilleures performances dans leurs traitements :
Le format d'en-tête d'un paquet IPv6 est donné par [RFC2460]
(cf. figure 4).
La description des différents champs de l'en-tête est donnée ci-dessous.
Le champ version est le seul champ qui occupe la même place dans les paquets IPv6 et IPv4. Sa valeur est 6.
Dans la version standardisée par [RFC2460] un champ classe de
trafic codé sur 8 bits permet la différenciation de services
conformément à [RFC2474].
Le champ classe de trafic est aussi appelé dans les paquets IPv4, l'octet DiffServ (DS). Il prend la place du champ ToS initialement défini dans la spécification d'IPv4. Pour mieux comprendre l'utilisation de ce champ, se référer à [RFC2474].
Ce champ contient un numéro unique choisi par la source qui a pour but
de faciliter le travail des routeurs et de permettre la mise en
oeuvre les fonctions de qualité de services comme RSVP
(Resource reSerVation setup Protocol) [RFC2205]. Cet
indicateur peut être considéré comme une marque pour un contexte dans
le routeur. Le routeur peut alors faire un traitement particulier :
choix d'une route, traitement en «temps-réel» de
l'information, ...
Avec IPv4, certains routeurs, pour optimiser le traitement, se basent
sur les valeurs des champs adresses de la source et de destination,
numéros de port de la source et de destination et protocole pour
construire un contexte. Ce contexte sert à router plus rapidement les
paquets puisqu'il évite de consulter les tables de routage pour chaque
paquet. Ce contexte est détruit après une période d'inactivité.
Avec IPv6, cette technique est officialisée. Le champ identificateur
de flux peut être rempli avec une valeur aléatoire qui servira à
référencer le contexte. La source gardera cette valeur pour tous les
paquets qu'elle émettra pour cette application et cette destination.
Le traitement est optimisé puisque le routeur n'a plus à consulter que
cinq champs pour déterminer l'appartenance d'un paquet. De plus si une
extension de confidentialité est utilisée, les informations concernant
les numéros de port sont masquées aux routeurs intermédiaires.
Contrairement à IPv4, ce champ, sur deux octets, ne contient que la taille des données utiles, sans prendre en compte la longueur de l'en-tête. Pour des paquets dont la taille des données serait supérieure à 65535 ce champ vaut 0 et l'option jumbogramme [RFC2675] de l'extension de «proche en proche» est utilisée.
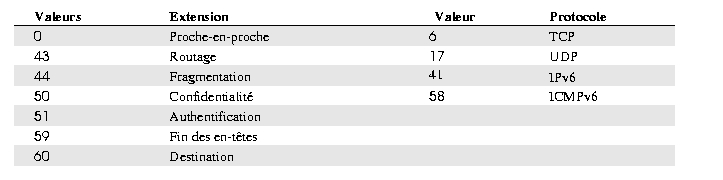
Ce champ a une fonction similaire au champ protocole du paquet IPv4. Il identifie tout simplement le prochain en-tête (dans le même datagramme IPv6). Il peut s'agir d'un protocole (de niveau supérieur ICMP, UDP, TCP, ...) ou d'une extension (cf. liste des extensions figure 5) .
Ce champ remplace le champ «TTL» (Time-to-Live) en IPv4. Sa valeur (sur 8 bits) est décrémentée à chaque noeud traversé. Si cette valeur atteint 0 alors que le paquet IPv6 traverse un routeur, il sera rejeté avec l'émission d'un message ICMPv6 d'erreur.
On ne traitera pas les extensions ici, voir [Cizault 99] pour de plus
amples détails. On peut juste préciser que les extensions d'IPv6
peuvent être considérées comme un prolongement de l'encapsulation d'IP
dans IP. À part l'extension de proche-en-proche traitée par tous les
routeurs intermédiaires, les autres extensions ne sont prises en
compte que par les équipements destinataires du paquet.
Une extension a une longueur multiple de 8 octets. Elle commence par un champ en-tête suivant d'un octet qui définit le type de données qui suit l'extension : une autre extension ou un protocole de niveau 4 (voir tableau 5).
Pour les extensions à longueur variable, l'octet suivant contient la longueur de l'extension en mots de 8 octets, le premier n'étant pas compté (une extension de 16 octets a un champ longueur de 1).
Une adresse IPv4 est un mot de 32 bits tandis qu'une adresse IPv6
est un mot de 128 bits. La taille des adresses a donc été quadruplée,
ce qui permet d'obtenir un espace adressable en IPv6 nettement plus
large que celui en IPv4.
Notons que, comme en IPv4, un adresse IPv6 est associée à une interface et non pas à une machine.
Un des problèmes majeurs d'IPv4 est la croissance incontrôlée des
tables de routages. Ce phénomène est dû à une mauvaise agrégation des
adresses dans les tables. Une amélioration a été apportée par CIDR
(voir [RFC1519]), mais en pratique, il s'avère que c'est
insuffisant. En effet, les adresses IPv4 sont trop courtes pour
permettre une bonne structuration et il faut assumer la charge des
adresses déjà allouées.
Pour concevoir une bonne agrégation, il est nécessaire de structurer
l'Internet en plusieurs niveaux : le premier niveau est le site, au
niveau supérieur se trouvent les prestataires de connectivité IP et au
niveau le plus haut on trouve les très gros prestataires qui servent
de transporteurs intercontinentaux. Les prestataires IP peuvent être
eux-mêmes structurés en plusieurs niveaux, car un prestataire peut
revendre de la connectivité IP tout en étant lui-même client d'un
autre prestataire.
À chaque niveau, le routage doit avoir une vision globale de
l'ensemble des niveaux inférieurs et fournir une vision aussi globale
que possible au niveau supérieur. On peut donc distinguer différents
niveaux conceptuels d'adressage : pour les grands transporteurs, pour
les fournisseurs d'accès et pour le découpage fin des sites. À ces
différents niveaux correspondent différentes politiques de plan d'adressage,
de routage et d'agrégation. La taille des adresses IPv6
permet de définir simplement ces niveaux en attribuant un certain
nombre de bits à chacun.
Le choix du plan d'adressage a fait l'objet de nombreux débats au sein de l'IETF. Nous présenterons le plan d'adressage actuellement retenu.
D'après [RFC2373], la représentation textuelle d'une adresse IPv6 se fait en découpant le mot de 128 bits de l'adresse en 8 mots de 16 bits, chacun d'entre eux étant représenté en hexadécimal et séparé par le caractère «:». Par exemple :
FEDC:BA98:7654:3210:EDBC:A987:6543:210FDans un champ, il n'est pas nécessaire d'écrire les zéros placés en tête. En outre plusieurs champs nuls consécutifs peuvent être abrégés par «::». Ainsi les deux notations suivantes sont équivalentes :
FEDC:0000:0000:0000:0400:A987:0043:210F
FEDC::400:A987:43:210F
Plus particulièrement, l'adresse formée uniquement par des zéros est représentée comme suit :
::
Naturellement, pour éviter toute ambiguïté, l'abréviation «::» ne
peut apparaître qu'une fois au plus dans une adresse.
La représentation des préfixes IPv6 est similaire à la notation CIDR [RFC1519] utilisée pour les préfixes IPv4. Un préfixe IPv6 est donc représenté par la notation :
adresse-ipv6 / longueur-du-préfixe-en-bitsLes formes abrégées avec «::» sont autorisées :
3EDC:BA98:7654:3210:0000:0000:0000:0000/64Enfin on peut combiner l'adresse d'une interface et la longueur du préfixe réseau associé en une seule notation :
3EDC:BA98:7654:3210:0:0:0:0/64
3EDC:BA98:7654:3210::/64
::/0 (défaut)
3EDC:BA98:7654:3210:945:1321:ABA8:F4E2/64
IPv6 reconnaît trois types d'adresses : unicast,
multicast et anycast.
Le type unicast, est le plus simple. Une adresse de ce type désigne
une interface unique. Un paquet envoyé à une telle adresse sera donc
remis à l'interface ainsi identifiée.
Une adresse de type multicast désigne un groupe d'interfaces qui en
général appartiennent à des équipements différents pouvant être situés
n'importe où dans l'Internet. Lorsqu'un paquet a pour destination une
adresse de type multicast, il est acheminé par le réseau à toutes les
interfaces membres de ce groupe. Il faut noter qu'il n'y a plus
d'adresses de type broadcast comme sous IPv4 ; elles sont
remplacées par des adresses de type multicast.
Le dernier type, anycast, est nouveau en IPv6. Les adresses anycast ont deux points communs avec les adresses unicast : elles sont allouées dans le même espace d'adressage et ont les mêmes formats. Comme dans le cas du multicast, une adresse de type anycast désigne un groupe d'interfaces, la différence étant que lorsqu'un paquet a pour destination une telle adresse, il est routé à un seul des éléments du groupe et non pas à tous. C'est, par exemple, le plus proche au sens de la métrique des protocoles de routage. Ce type d'adresse est encore en cours d'expérimentation et est réservé pour le moment aux routeurs. Pour plus de détail sur la notion d'adresse anycast et sur son utilité, se reporter à [RFC2373]. Ce type d'adresse servira pour des applications où le un noeud d'un réseau cherche à communiquer avec un des routeurs d'un sous-réseau distant. Par exemple quand un hôte mobile doit communiquer avec un des agents mobiles sur son propre sous-réseau.
L'adresse de type plan agrégé est présentée
figure 6. Il s'agit du dernier plan
d'adressage proposé à l'IETF (Aggregatable Global Unicast
Address Format) [RFC2374]. Ce plan garde la structure classique
de l'adressage IP où une adresse IP comprend à la fois un préfixe
désignant le réseau auquel l'interface est rattachée et une partie
identifiante locale.
Ce plan d'adressage comprend trois niveaux de hiérarchie :
La topologie publique est constituée par l'ensemble des prestataires et des points d'échange de connectivité IP. Le format de la topologie publique est le suivant :
Le format de la topologie de site est le suivant :
On retrouve ici la notion d'agrégation mise en oeuvre par CIDR, mais de manière totalement naturel. En effet, un gros fournisseur d'accès Internet (FAI) se verra allouer une adresse en ::/32. Ceci fixera donc une partie des bits du NLA et il pourra découper les adresses dont il dispose en fonction des besoins de ses clients. Un énorme FAI aura une adresse de type ::/28 par exemple.
L'idée d'allouer des préfixes IPv6 de longueur variable (agrégation) limite dès le départ le gaspillage des adresses IPv6 et garantit à long terme la maîtrise de la taille des tables de routage IPv6. Si l'on ajoute à ces précaution le fait que l'espace d'adressage IPv6 soit nettement plus large que celui d'IPv4, on peut dire que le risque de pénurie d'adresses IPv6 est écarté. En effet, en prenant en compte les estimations les plus pessimistes et les plus optimistes [BM95]3, on obtient l'encadrement suivant où l'unité est le nombre d'adresses par mètre carré de surface terrestre (océans compris) :
Il faut donc bien comprendre que l'adressage IPv6 se fait de manière descendante, en allant du plus général (un FAI) vers l'interface réseau d'une machine sur un site. A chaque étape, un «bout d'adresse» est fixé.
Ces adresses sont utilisées par de nombreux dispositifs tels que le protocole de découverte des voisins (NDP : Neighbor Discovery Protocol), de découverte des routeurs (RDP : Router Discovery Protocol).
Une adresse site-local est construite en concaténant le préfixe FEC0::/48, un champ de 16 bits qui permet de définir plusieurs sous-réseaux, et les 64 bits de l'identificateur d'interface.
Les adresses broadcast ont disparu du protocole IPv6. La raison de
cette disparition est que l'émission d'un paquet broadcast est très
pénalisante pour toutes les machines se trouvant sur le même lien. En
effet, sur chaque machine le paquet est remonté de la carte réseau
jusqu'à la pile IP où il pourra éventuellement être ignoré.
Une adresse multicast est une adresse désignant un groupe
d'interfaces donné. Un paquet envoyé à une telle adresse sera
donc délivré à toutes les interfaces du groupe. Une interface
est libre de s'abonner à un groupe ou de le quitter à tout moment. Un
groupe existe (et donc l'adresse qui lui est affectée) tant qu'au
moins une interface y appartient.
Une adresse multicast est caractérisée par le préfixe FF00::/8. Le format de l'adresse est donné figure 7.
Le champ drapeaux («flags») est un mot de 4 bits. Les 3
premiers bits sont réservés et doivent être initialisés à zéro. Le
dernier bit, nommé T, s'il est positionné à zéro indique que
l'adresse est permanente (auquel cas, elle a été nécessairement
attribuée par une autorité compétente de l'Internet), sinon l'adresse
est temporaire («transient address»).
Le champ suivant indique la portée (scope) de l'adresse (niveau de diffusion). Les valeurs actuellement définies sont les suivantes :
0 réservé 1 équipement (node-local scope) 2 lien (link-local scope) 5 site (site-local scope) 8 organisation (organization-local scope) E global (global scope) F réservé
L'intérêt principal du niveau de diffusion est de permettre de
confiner un paquet à l'intérieur d'une zone bien déterminée. Cette
méthode est plus rigide mais plus sure qu'en IPv4, où la portée d'un
paquet multicast est définie essentiellement en fonction du champ
«durée de vie».
Il faut noter qu'une adresse temporaire n'est valide qu'au sein de son
niveau de diffusion alors qu'une adresse permanente a un sens qui est
indépendant de son niveau de diffusion.
Notons également qu'une interface sur un lien donné doit automatiquement s'abonner aux groupes multicast particuliers suivants :
Enfin, un paquet IPv6 ne peut en aucun cas avoir pour adresse source une adresse multicast (ou anycast d'ailleurs).
Le protocole de contrôle d'IP a été revu. Dans IPv4, ICMP
(Internet Message Control Protocol) sert à la détection
d'erreurs (par exemple : équipement inaccessible, durée de vie
expirée, ...), aux tests (par exemple ping) et à la
configuration automatique des équipements (redirection ICMP,
découverte des routeurs). Ces trois fonctions sont mieux définies dans
IPv6. De plus, grâce au sous-protocole MLD (Multicast
Listener Discovery) [RFC2710], ICMPv6 intègre les fonctions de
gestion des groupes de multicast qui sont effectuées par IGMP
(Internet Group Management Protocol) dans IPv44. ICMPv6 reprend également les fonctions
du protocole ARP utilisé par IPv4.
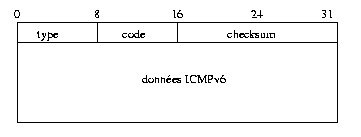
Le format commun des paquets ICMPv6 est donné figure 8 :
Voici une description sommaire des champs de l'en-tête ICMPv6 :
Les messages ICMPv6 de compte rendu d'erreur contiennent dans la
partie données le paquet IPv6 qui a provoqué l'erreur.
Pour plus de détails, on se reportera à [Stevens 94] pour la description d'ICMPv4 et à [Cizault 99,RFC2463] pour la description d'ICMPv6.
Le protocole de découverte des voisins (Neighbor Discovery) [RFC2461] permet à un équipement de s'intégrer dans l'environnement de réseau local, c'est-à-dire le lien sur lequel sont physiquement transmis les paquets IPv6. C'est grâce à ce protocole qu'il devient possible de dialoguer avec les équipements connectés au même support (stations et routeurs). Il est important de noter que pour un équipement donné, la découverte des voisins ne consiste pas à établir une liste exhaustive de tous les autres équipements connectés sur le lien. En effet, il s'agit de gérer uniquement ceux avec qui il dialogue.
Le protocole utilise 5 types de messages ICMPv6. Le champ «nombre de sauts» de l'en-tête IPv6 contient la valeur5 255. Le protocole remplit les différentes fonctions qui suivent.
Le principe est très proche du protocole ARP que l'on trouve avec IPv4. La principale différence vient de l'emploi de messages standards ICMPv6 à la place de la définition d'un autre protocole de niveau 3. Cela confère une plus grande souplesse d'utilisation en particulier sur les réseaux qui ne supportent pas la diffusion (tels que ATM, Frame Relay, ...). Comme pour IPv4, ce protocole construit des tables de mise en correspondance entre adresses IPv6 et adresses physiques. Une requête de résolution d'adresse, est une sollicitation de voisin (voir ci-dessous) véhiculée par un paquet ICMPv6 dont l'adresse destination est l'adresse multicast sollicité associée au voisin en question.
Cette fonction appelée encore «NUD» (Neighbor Unreachability Detection) n'existe pas en IPv4. Elle permet d'effacer dans le cache de voisins (ce cache est analogue à la table arp dans IPv4) d'un équipement les entrées correspondant aux voisins devenus inaccessibles (panne, changement d'adresse, ...). Si un routeur devient inaccessible, la table de routage peut être modifiée pour prendre en compte un autre routeur.
La configuration automatique des équipements est un atout principal d'IPv6. Plusieurs fonctionnalités du protocole de découverte des voisins y sont impliquées :
Ce message est utilisé quand un routeur connaît une route meilleure
(en nombre de sauts) pour aller à une destination.
La technique de redirection est la même que dans IPv4. Un équipement
terminal ne connaît que les préfixes des réseaux auxquels il est
directement attaché et l'adresse d'un routeur par défaut. Si la route
peut être optimisée, le routeur par défaut envoie ce message pour
indiquer qu'une route plus courte existe. En effet, avec IPv6, comme
le routeur par défaut est appris automatiquement, la route n'est pas
forcément la meilleure.
Un autre cas d'utilisation, particulier à IPv6, concerne des stations
situées sur un même lien physique mais ayant des préfixes différents.
Ces machines passent dans un premier temps par le routeur par défaut.
Ce dernier les avertit qu'une route directe existe. On parle alors de
redirection externe.
Dans le cas le plus extrême, on peut imaginer en IPv6 qu'un équipement
peut être configuré pour dialoguer uniquement avec son routeur par
défaut. ICMPv6 «redirect» est alors utilisé pour informer
l'équipement des destinataires sur le même lien.
Les différentes fonctionnalités de découverte des voisins utilisent 5 messages : 2 pour le dialogue entre un équipement et un routeur, 2 pour le dialogue entre voisins et un dernier pour la redirection. Chacun de ces messages peut contenir des options.
Le message de sollicitation de routeur est émis par un équipement au démarrage pour recevoir plus rapidement des informations du routeur. Ce message est émis à l'adresse IPv6 de multicast réservée aux routeurs sur le même lien ff02::2. Si l'équipement ne connaît pas encore son adresse source, l'adresse non spécifiée est utilisée.
Ce message est émis périodiquement par les routeurs ou en réponse à un message de sollicitation de routeur par un équipement.
Ce message permet d'obtenir des informations d'un voisin, c'est-à-dire situé sur le même lien physique (ou via des ponts). Le message peut être envoyé au voisin soit explicitement (en unicast) soit vers l'adresse multicast sollicité associée à ce voisin. Dans le cas de la détermination de l'adresse physique, il correspond à la requête ARP du protocole IPv4.
Ce message est émis en réponse à une sollicitation, mais il peut aussi être émis spontanément pour propager plus rapidement une information. Dans le cas de la détermination d'adresse physique, il correspond à la réponse ARP du protocole IPv4.
Un message de redirection («Redirect») peut correspondre soit à une indication de redirection similaire à celle vue dans IPv4 (meilleur routeur de sortie), soit à une redirection externe (spécifique à IPv6) pour déclencher une communication directe avec la machine destination.
Traditionnellement, la configuration d'une interface réseau d'une machine demande une configuration manuelle. C'est un travail souvent long et fastidieux. Avec IPv6, cette configuration est automatisée donnant par là-même des caractéristiques de fonctionnement immédiat («plug and play») à l'interface réseau. La configuration automatique signifie qu'une machine obtient toutes les informations nécessaires à sa connexion à un réseau local IP sans aucune intervention humaine. En particulier, l'autoconfiguration d'adresses IPv6, qui sera décrite dans la section qui suit, se trouve au coeur de la configuration automatique des interfaces IPv6. Dans le cas idéal, un utilisateur quelconque déballe son nouvel ordinateur, le connecte au réseau local et le voit fonctionner sans devoir y introduire des informations de «spécialiste».
L'autoconfiguration d'adresses IPv6 a pour objectifs :
Le processus d'autoconfiguration d'adresses d'IPv6 comprend la création d'une adresse lien-local, la vérification de son unicité, la détermination de l'adresse (ou des adresses) unicast globale(s). IPv6 spécifie deux méthodes d'autoconfiguration pour l'adresse unicast globale :
Le rôle du routeur est important dans l'autoconfiguration. Il dicte à la machine la méthode à retenir et fournit éventuellement les informations nécessaires à sa configuration.
À l'initialisation de son interface, la machine construit un identificateur pour cette interface qui doit être unique au lien. Cet identificateur a été dans sa première version l'adresse MAC de la machine ; actuellement il est sous le format de l'identificateur EUI-64. Le principe de base de la création d'adresse IPv6 est de concaténer un préfixe à l'identificateur. L'adresse lien-local est créée en prenant le préfixe lien-local (FE80::/64) qui est fixé. L'adresse ainsi constituée est encore interdite d'usage. Elle possède un état provisoire car la machine doit encore vérifier l'unicité de cette adresse sur le lien au moyen de la procédure de détection d'adresse dupliquée. Si la machine détermine que sa création d'adresse lien-local a échoué (c'est-à-dire qu'elle n'est pas unique), l'autoconfiguration s'arrête et une intervention manuelle est nécessaire. Une fois que l'unicité de l'adresse lien-local a été vérifiée, l'adresse provisoire devient une adresse valide pour l'interface.
L'autoconfiguration sans état [RFC2462]) ne demande ni de configuration manuelle des machines, ni de serveurs supplémentaires mais juste une configuration minimale pour les routeurs. Elle se sert du protocole ICMPv6 et peut fonctionner sans la présence de routeurs. Elle nécessite cependant un sous-réseau à diffusion. Cette méthode ne s'applique que pour les machines et ne peut être retenue pour la configuration des routeurs. Selon le principe de base de l'autoconfiguration sans état, une machine construit son adresse IPv6 à partir d'informations locales et d'informations fournies par un routeur. En fait le routeur fournit à la machine les informations sur le sous-réseau associé au lien, il lui donne le préfixe qui lui servira à construire l'adresse unicast globale de l'interface selon le plan d'adressage agrégé vu précédemment (concaténation du préfixe et de l'identificateur d'interface). Le préfixe provient du message d'annonce de routeurs et plus précisément de l'option «information sur un préfixe».
L'autoconfiguration avec état permet à une machine IPv6 d'obtenir les
adresses et/ou d'autres informations de configuration par
l'intermédiaire d'un serveur. Tout le mécanisme d'autoconfiguration
avec état est bâti sur le modèle client-serveur et repose sur
l'utilisation du protocole DHCPv6 (Dynamic Host Configuration Protocol
for IPv6). Un paramètre de configuration est une
information utile au client DHCPv6 pour configurer son interface
réseau et communiquer par la suite sur son lien ou sur
l'Internet. Ceci comprend notamment les adresses pour le client, le
serveur de nom, le nom de domaine, ...Pour les adresses, par
exemple, le serveur maintient une table lui permettant de connaître
les adresses déjà allouées. L'ensemble des adresses gérées par le
serveur est créé par l'administrateur du site. Le serveur DHCP ne se
trouve pas forcément sur le même lien que le client et, dans ce cas,
les échanges DHCPv6 passent par des relais. Grâce à ceux-ci, le
serveur peut maintenir la configuration des machines situées sur
plusieurs liens différents.
Conformément au modèle client-serveur, les échanges se composent de requêtes et de réponses. Une transaction est pratiquement toujours entamée à l'initiative d'un client par une requête DHCP. La fiabilité de la transaction est assurée par le client, qui réémet sa requête DHCP jusqu'à ce qu'il reçoive une réponse ou qu'il soit certain que le serveur DHCP est indisponible. DHCPv6 est un protocole d'application qui utilise le protocole de transport UDP au-dessus d'IPv6. Les travaux sur DHCPv6 ont démarré en 1995. La spécification de DHCPv6 a provoqué de vives controverses au sein du groupe de travail «dhc», ce qui explique qu'elle est toujours à l'état d'«Internet Draft». C'est probablement le protocole dont la standardisation va mettre le plus de temps 6. Les discussions autour de DHCPv6 semblent avoir redémarrées récemment et il y a des chances qu'elles convergent rapidement vers un RFC.
La France fait partie des premiers pays du monde qui s'est intéressé à la mise en oeuvre et à l'expérimentation du protocole IPv6. En effet, dès l'apparition des premières spécifications d'IPv6, des chercheurs de l'INRIA et de l'IMAG se sont penchés sur une implémentation pour les systèmes Unix FreeBSD/NetBSD, appelée communément «souche INRIA». Parallèlement, des chercheurs issus de milieux académiques et industriels ont formé un groupe de travail, le G6, et se sont fixés dans un premier temps les trois objectifs suivants :
Le groupe G6 tient à jour un site Web (http://Phoebe.urec.fr/G6/) qui
donne des renseignements sur les activités du groupe (plate-formes,
administration du G6bone, présentations, ...). Ce site fournit
également des pointeurs vers d'autres sites traitant d'IPv6 (souvent
en anglais). En voici quelques uns :
ARP (Address Resolution Protocol)
Protocole de résolution d'adresse IPv4 en une adresse de niveau
liaison (typiquement Ethernet).
ICMP(v6) (Internet Control Message Protocol (version 6))
Protocole de contrôle d'IP. Dans IPv4, ICMP sert à la détection
d'erreurs, aux tests et à la configuration automatique des
équipements. Ces trois fonctions sont mieux définies dans IPv6. De
plus, grâce au sous-protocole MLD, ICMPv6 intègre les fonctions de
gestion des groupes de multicast qui sont effectuées par IGMP dans
IPv4. ICMPv6 reprend également les fonctions du protocole
ARP utilisées par IPv4.
IGMP (Internet Group Management Protocol)
Protocole de gestion des groupes multicast en réseau IP local. IGMP
et IGMPv2 sont spécifiques à IPv4. MLD qui est un dérivé d'IGMPv2 en
est l'équivalent en IPv6.
IP (Internet Protocol)
Protocole de niveau réseau (couche 3 du modèle OSI) utilisé dans
l'Internet. IPv4 est la version actuelle et IPv6 est la version
future, en cours de déploiement.
MLD (Multicast Listener Discovery)
Voir IGMP.
Multicast
Transmission simultanée (diffusion restreinte) de données d'une
source vers un certain groupe de noeuds.
NA (Neighbor Advertisement)
Annonce de voisin dans le cadre du protocole ND. C'est
l'équivalent de la réponse ARP. Un message NA
vient en réponse à une requête NS.
ND (Neighbor Disvovery)
Découverte des voisins. Protocole de la couche réseau, associé à
IPv6. Il remplace et couvre le protocole ARP d'IPv4.
NS (Neighbor Sollicitation)
Sollicitation de voisin dans le cadre du protocole ND. Permet à
un équipement de résoudre l'adresse IPv6 en adresse liaison
(équivalent d'une requête ARP).
SAA (Stateless Address Autoconfiguration)
Autoconfiguration sans état. Cette méthode d'autoconfiguration
est utilisée quand la gestion stricte des adresses
attribuées n'est pas nécessaire au sein d'un site. Le processus
d'autoconfiguration d'adresses d'IPv6 comprend la création d'une
adresse lien-local, la vérification de son unicité, la
détermination de l'adresse (ou des adresses) unicast globale(s). IPv6
spécifie deux méthodes d'autoconfiguration pour l'adresse unicast
globale : l'autoconfiguration sans état (SAA) et
l'autoconfiguration avec état (DHCPv6)